学习总结
不定时更新, 该时间段学到的新知识新技能
java 分析
书籍
1,/root/下载/java 分析/《_深入理解Java虚拟机_JVM高级特性与最佳实践 第2版_220_.pdf》
2./root/下载/java 分析/深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)周志明.pdf
3/root/下载/java 分析/《IntelliJ IDEA快捷键大全@www.java1234.com.pdf》
远程debug
1 | ## jvm 参数中加入以下命令 |
jstack/javacore 导出
供程序卡死时分析使用
如果jstack 看到有locked object ox121141
但是 搜不到 具体的object 是哪个
说明 jstack 打晚了, 0x1e1e31已经看不到了
需要在这之前jstack
才能看到线程卡在 哪个堆栈上
1 | jstack <pid> |
heapdump 生成
供程序内存溢出(OOM) 、程序内存使用现状 分析使用
1 | 1. 默认会有coredump文件生成,以.dmp 文件结尾 |
3.gc文件生成
1 | -Xloggc:./tmp/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps |
1 | 实时查看 |
class not found 分析
1 | class_info = jad class_full_name |
arthas 分析
查看JVM class命令
1
sc -d -f demo.MathGame
查看方法的入参和异常
1
watch *.CommonTest test '{params,returnObj,throwExp}' -x 5 -e
tomcat 类加载机制
tomcat 打破了双亲委派机制,jvm 默认类加载器appclassloader 会启动tomcat自定义的类加载器
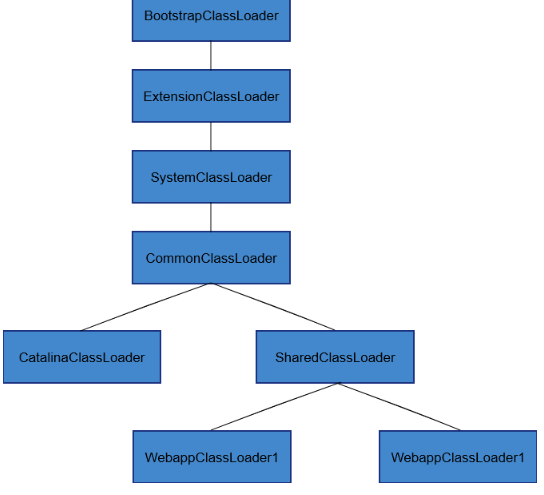
自定义的类加载 parallelwebappclassloader 会分别加载webapps 下的各个应用jar包,完成各个应用的启动相互隔离
也因此,springboot 项目出现明明 jvm 里面已经加载了某个class,但是 springboot仍然报错 no class found,是因为这个class 可能被其他classloader加载了,单与使用到这个class的类所在的类加载器不一致,且使用类为父加载器,那个class为子类加载,导致找不到class
dubbo 分析
1./root/下载/dubbo 分析/《dubbo源码分析系列@www.java1234.com.pdf》
2./root/下载/dubbo 分析/ 《dubbo源码解析2.0@www.java1234.com.pdf》
3.dubbo spi 加载流程
注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
整体流程
提供方:
首先暴露到本地netty,用dubboProtocal 读取预先获取到的协议(dubbo,http)以及端口
registryProtocal :用registryService注册服务->zk
并且保存每一条调用传过来的url,需要的invoker,到map中,这样与消费方netty通信时,就知道,到底用哪个invoker去执行了对外暴露服务
消费方:
启动时,读取配置,从zk获取服务提供方列表,并缓存到本地
执行调用逻辑时,生成一个代理对象proxy,所有的服务调用,使用proxy类生成的对象统一完成
proxy中,首先进行一系列预处理, 然后用dubboReference创建一个netty客户端,设置自己的ip,port, 如果没有缓存,从zk上订阅服务,获取服务具体提供方的ip:port; 包装成调用url->调用invoker的缓存, 如果有缓然后从缓存中选择一个提供方ip:port 用netty框架进行网络通信,向提供方传输序列化后的参数(包括要调用的服务名,入参等) 提供方nettyChannel接受到请求,开始处理, 通过一个proxy对象,统一完成调用过程,中间进过一些逻辑判断,根据url,从本读缓存中,读取url对应invoker,在dubboInvoker中完成服务具体实现接口的调用,包括拦截器中的处理 并将结果用netty网络通信传输后返回给消费方
dubbo 2.7 新特性
元数据
元数据:描述数据的数据,
在服务治理中,例如服务接口名,重试次数,版本号等等都可以理解为元数据
Dubbo 2.7 进行改动,只将真正属于服务治理的数据发布到注册中心之中,大大降低了注册中心的负荷。
同时,将全量的元数据发布到另外的组件中:元数据中心。
元数据中心目前支持 redis(推荐),zookeeper。
示例:使用 zookeeper 作为元数据中心
1
<dubbo:metadata-report address="zookeeper://127.0.0.1:2181"/>
2.7 中,如果不进行额外的配置,zookeeper 中的数据格式仍然会和 Dubbo 2.6 保持一致,保持兼容性
开启简化:
1
<dubbo:registry address=“zookeeper://127.0.0.1:2181” simplified="true"/>
实例:
原来:dubbo%3A%2F%2F192.168.43.178%3A28087%2Forg.apache.dubbo.demo.DemoService%3Fanyhost%3Dtrue%26application%3Ddemo-provider%26deprecated%3Dfalse%26dubbo%3D2.0.2%26dynamic%3Dtrue%26generic%3Dfalse%26interface%3Dorg.apache.dubbo.demo.DemoService%26metadata-type%3Dremote%26methods%3DsayHello%2CsayHelloAsync%26pid%3D6414%26release%3D%26side%3Dprovider%26timestamp%3D1594308439251
现在:dubbo://30.5.120.185:20880/org.apache.dubbo.demo.api.DemoService? application=demo-provider& dubbo=2.0.2& release=2.7.0& timestamp=1552975501873
对于那些非必要的服务信息,仍然全量存储在元数据中心之中
{“parameters”:{“side”:”provider”,”release”:”2.7.8-SNAPSHOT”,”methods”:”sayHello,sayHelloAsync”,”deprecated”:”false”,”qos.port”:”22222”,”dubbo”:”2.0.2”,”interface”:”org.apache.dubbo.demo.DemoService”,”generic”:”false”,”timeout”:”300”,”revision”:”2.7.8-SNAPSHOT”,”metadata-type”:”remote”,”application”:”demo-provider”,”dynamic”:”true”,”anyhost”:”true”},”canonicalName”:”org.apache.dubbo.demo.DemoService”,”codeSource”:”dubbo-demo-interface-2.7.8-SNAPSHOT.jar”,”methods”:[{“name”:”sayHelloAsync”,”parameterTypes”:[“java.lang.String”],”returnType”:”java.util.concurrent.CompletableFuture”},{“name”:”sayHello”,”parameterTypes”:[“java.lang.String”],”returnType”:”java.lang.String”}],”types”:[{“type”:”java.lang.String”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},{“type”:”char”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},{“type”:”int”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},{“type”:”java.util.concurrent.CompletableFuture”,”properties”:{“result”:{“type”:”java.lang.Object”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},”stack”:{“type”:”java.util.concurrent.CompletableFuture$Completion”,”properties”:{“next”:{“type”:”java.util.concurrent.CompletableFuture$Completion”,”$ref”:”java.util.concurrent.CompletableFuture$Completion”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},”status”:{“type”:”int”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”}},”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”}},”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},{“type”:”java.lang.Object”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},{“type”:”java.util.concurrent.CompletableFuture$Completion”,”properties”:{“next”:{“type”:”java.util.concurrent.CompletableFuture$Completion”,”$ref”:”java.util.concurrent.CompletableFuture$Completion”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”},”status”:{“type”:”int”,”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”}},”typeBuilderName”:”org.apache.dubbo.metadata.definition.builder.DefaultTypeBuilder”}]}
元数据路径
管理平台与元数据交互
配置中心
在 Dubbo 中,配置中心主要承担了两个作用
- 外部化配置。启动配置的集中式存储
- 服务治理。服务治理规则的存储与通知
示例:使用 Zookeeper 作为配置中心
1
<dubbo:config-center address="zookeeper://127.0.0.1:2181"/>
Netty
入门
1.(netty-server 、netty-client 模板):/root/code/IdeaProjects/netty-project
### 指南
/root/下载/netty 分析/《Netty权威指南 PDF电子书下载 带目录书签 完整版.pdf》
Nginx
启动命令
Nginx 启动命令的格式: Nginx 执行文件- c Ng inx 配置文件所在地址
( 1 )用默认配置文件直接启动。
/usr/local/nginx/sbin/nginx
或
nginx
(2 )指定配置文件启动。
nginx - c /usr/local/nginx/conf/nginx . conf
(3 )其他方式启动。
service nginx start
停止 Nginx
停止 Nginx 的 方法有 3 种 : 从容停止、快速停止和强制停止 。一般都是通过发送系统信号
给主进程 的 方式来停止 Ng inx o
( 1) 查看 Nginx 的主进程号 。
ps - ef I grep nginx
15| 直播系统开发:基于 Nginx 与 Nginx-rtmp-module
该命令在 1.3 . 3 节中介绍过 ,这里不 再赘述 。
( 2 )从容停止。
kill
QUIT 主进程号
或
killQUIT
/usr/local/nginx/logs/nginx .pid
如果在 nginx.conf 配置文件中指 定 了 pid 文件存放的路径 ,则该文件 中存放的就是 Nginx
当前的主进程号,其默认被放在 Nginx 安装目录 的 logs 目 录下。
(3 )快速停止 。
killTERM 主进程号
(4 )强制停止 。
pkill
-9
口 gin x
( 5 )其他停止方式 。
还可以用其他方式停止 Nginx 服务 :
service nginx stop
或
nginx - s stop
重启
如果修改了 N ginx 的 配置文件 , 要想让新配置的文件生效 ,就得重启 Nginx 。同样 ,可以
发送系统信号给 Ngi nx 主进程来重启 Nginx 。
C I )验证配置文件的正确性 。
验证配置文件的正确性使用以下命令:
nginx - t
该命令会默认检查/usr/local/nginx/conf/nginx.conf 文件 。 如果要测试指 定 的配置文件,则执
行以下命令(该命令中的文件路径要改成待测试的配置文件路径) :
nginx -t -c /usr/local/nginx/conf/nginx.conf
全链路配置
首先$request_id 放在HEADER 中传到后端(<=> zpkin 中的 trace_id)
proxy_set_header HTTP_REQUEST_ID $request_id
设置前后调用关系
例如 zpkin中的spanid
docker
常用命令
1 | docker inspect 容器名字或者 ID | grep -i logpath |
ELK 搭建(日志中心基本搭建)
架构
(filebeat :logstash-forwarder 的升级版)

https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html
Spring cloud 集成 Sleuth
- demo :/root/code/IdeaProjects/cloud-sleuth-parent
- zipkin-server 作为服务端; backend作为提供方服务;client 作为消费方服务
- 不直接使用http传送链路信息;使用rabbitMQ作为分布式消息中间件
- backend 和 client 的链路信息发到MQ; zipkin 从MQ消费链路信息;并且zipkin获取到后存入mysql
logback 新增json文件
定义一个log 文件
1
2<property name="LOG_FILE" value="${LOG_FILE}"/>
使用:-D 参数加上,即启动参数中加上 -DLOG_FILE=/root/logs/cloud.log设置滚动策略
1
2
3
4<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>- 设置具体执行哪些打印策略,以及需要记录哪些级别的日志
1
2
3
4
5
6<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs-->
<appender-ref ref="logstash"/>
<!-- <appender-ref ref="flatfile"/>-->
</root>
Elasticsearch 全文搜索引擎
底层使用开源库:Lucene,但是不能直接使用,需要使用api调用
分布式数据库
1
2
3## 不能用root用户启动
## 需要切换到其他用户 su elasticsearch
./bin/elasticsearch流程
p -> rabbit c -> rabbit
rabbitMQ -> zipkin <-> elasticsearch
原理
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
elasticsearch使用教程
查看所有index(数据库):http://localhost:9200/_cat/indices?v
查看所有type:http://localhost:9200/_mapping?pretty=true
查看某个index下的所有数据:http://localhost:9200/zipkin-2020-07-01?pretty=true
filebeat 配置
原理:采集配置中的log文件,发送到logstash或者elasticsearch中
- input_type: log
- paths:
- /root/code/IdeaProjects/cloud-sleuth-parent/microservice-zipkin-client-backend/logs/backend.log.json
- paths:
output.elasticsearch:
hosts: ["localhost:9200"]output.logstash
hosts: ["localhost:5044"]- input_type: log
启动:./filebeat -e -c filebeat.yml -d “publish”
logstash 配置
设置pipline ,对接fileabeat发过来的日志
发送到elasticsearch
logstash 优化
logstash 使用grok filter 时,因为使用正则表达式,则对cpu、内存消耗较大
问题复现:特殊字符分割的日志,使用grok 匹配后转成json 格式,直接写正则匹配后压测,1并发持续压测,出现丢数据现象,基本上1小时入es一次,每次持续1-2分钟
优化思路: 借鉴条带化技术,kafka使用单独topic发送并且携带加密鉴权,消费前认证 + logstash 逻辑优化
具体实现:
kafka 添加sm512 加密配置
logstash 放弃使用正则匹配,改为字符串分割,保存到数组中,构造输出的json 格式,key:xx,value = array[i]
kafka 方面的调优
1.消费方个数 <= kafka的 partion个数
2.实现重复消费: 对消费方进行分组,即设置groupid
Prometheus 监控报警搭建
工作流程
(1)客户端 安装 xxx_exporter , 暴露监控数据获取的接口
(2)Prometheus Server 定时查询 exporter 暴露的接口,将查询到的监控数据,落 TSDB(时序数据库)
(3)Prometheus Server 暴露接口,可以查询某段时间内的监控数据
(4)AlertManager :告警模块,可以用一套告警集群对接 不同的Prometheus Server 集群
Prometheus Server 端
启动时 : 需要指定配置文件路径
exporter 编写
默认使用go 语言编写 : 定义 /metrics 接口 ,接口按采集格式,返回采集数据
有四类指标:Counter (累加指标)、Gauge (测量指标)、Summary (概略图)(占比)、Histogram (直方图)(占比)
https://www.jianshu.com/p/9646ce49f722
alertManager 报警rule 规则编写
prom sql 监控查询sql 编写
linux 运维
linux挂载ftp服务器目录
1 | sudo mount "\\\192.168.10.22\FTPServer" /ftp_tmp -o username=user,password=abcdefg -t cifs |
nvidia 显卡使用情况监控
1 | while true;do nvidia-smi && sleep 5;done; |
查看端口连接数
1 | netstat -an | grep 8080 | grep ESTABLISHED | wc -l |
AI
理论书籍
1.《机器学习》周志华
实战类 书籍
1./root/下载/AI 分析/《584756 大数据架构详解:从数据获取到深度学习.pdf》
工作实践
报警压缩:zabbix
(1)时间聚合
(2)内容相似度
(3)关联性
Spring Cloud
### ZUUL
拦截器类型 (pre、route、post、error 四种)
拦截器用法
type:设置类型
run:逻辑
order:同一类型的优先级:数字越小、优先级越大
### Ribbon
### 指南
/root/下载/ Spring Cloud 分析/《687039_Spring Cloud微服务全栈技术与案例解析.pdf》
IELTS
算法
各种loss 函数的选择:
| 2/3…分类一般用: | log-loss | |
|---|---|---|
| 回归场景 | 平方loss,即l2-loss | |
| 异常点检测 | l1-loss,即分位数回归:0.5,均方误差 | |
| 平滑 | Huber-loss: loss ->0,mSE;los->∞,mae |
修改loss:设置多个loss(即包含辅助loss)
两种方式:
1)每个loss 有权重 ,然后累加和
2) 不设置权重,进行concat 操作,构造出 [ loss1 ; loss2 ] ,然后反向传播,其实是对每个loss求了梯度,两个互不影响 ,这一种一般效果好,但是训练速度慢
调整bert参数
创建 传统特征工程
stacking: bert + 传统特征