模型压缩专题
模型压缩方法
- 知识蒸馏 Knowledge Distillation
- 网络剪枝 Network Pruning
- CNN架构设计 Architecture Design
- 参数量化 Weight Quantization
知识蒸馏
网络剪枝

简单来说就是让一个已经学完的模型中的神经元进行删减,让整个网路的更瘦。
Weight & Neuron Pruning
weight和neuron pruning差別在于
prune掉一個neuron就等于是把一個matrix的整个column全部砍掉。但如此一來速度就會比較快。因为neuron pruning后matrix整体变小,
但weight pruning大小不变,只是有很多空洞
What to Prune?
- 既然要Neuron Pruning,那就必须先要衡量Neuron的重要性。衡量完所有的Neuron后,就可以把比较不重要的Neuron刪減掉。
- 在这里我们介绍一个很简单可以衡量Neuron重要性的方法 - 就是看 batchnorm layer的Γ因子来决定neuron的重要性。 (by paper - Network Slimming)

要怎么操作?
- 为了避免复杂的操作,我们会将StudentNet(width_mult=α)的neuron经过筛选后移植到StudentNet(width_mult=β)。(α > β)
- 筛选的方法也很简单,只需要抓出每一個block的 batchnorm 的γ即可。
一些操作细节
- 假设model中间两层是这样的:
| Layer | Output # of Channels |
|---|---|
| Input | in_chs |
| Depthwise(in_chs) | in_chs |
| BatchNorm(in_chs) | in_chs |
| Pointwise(in_chs, mid_chs) | mid_chs |
| Depthwise(mid_chs) | mid_chs |
| BatchNorm(mid_chs) | mid_chs |
| Pointwise(mid_chs, out_chs) | out_chs |
则你会发现利用第二个BatchNorm来做筛选的时候,跟他的Neuron有直接关系的应该是该层的Depthwise(bn上面)&Pointwise(bn下面)以及上层的Pointwise。
因此再做neuron筛选时要记得将这四个(包括自己, bn)也要同时prune掉。
- 在Design Architecure內,model的一個block,名称所对应的Weight:
| # | name | meaning | code | weight shape |
|---|---|---|---|---|
| 0 | cnn.{i}.0 | Depthwise Convolution Layer | nn.Conv2d(x, x, 3, 1, 1, group=x) | (x, 1, 3, 3) |
| 1 | cnn.{i}.1 | Batch Normalization | nn.BatchNorm2d(x) | (x) |
| 2 | ReLU6 | nn.ReLU6 | ||
| 3 | cnn.{i}.3 | Pointwise Convolution Layer | nn.Conv2d(x, y, 1), | (y, x, 1, 1) |
| 4 | MaxPooling | nn.MaxPool2d(2, 2, 0) |
code:
1 | def network_slimming(old_model, new_model): |
MobileNetV1 VS MobileNetV2
MobileNetV1: Depthwise + Pointwise
- Depthwise
Depthwise卷积是指不跨通道的卷积,也就是说Feature Map的每个通道有一个独立的卷积核,并且这个卷积核作用且仅作用在这个通道之上
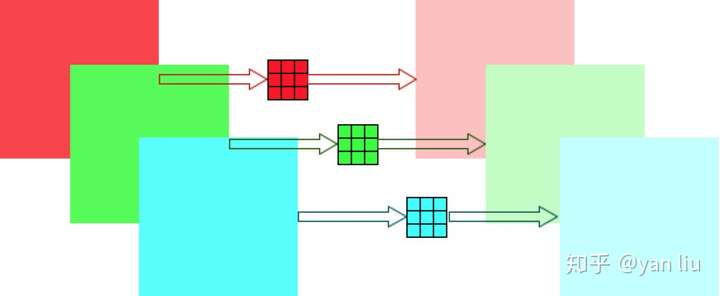
Pointwise
Depthwise卷积的操作虽然非常高效,但是它仅相当于对当前的Feature Map的一个通道施加了一个过滤器,并不会合并若干个特征从而生成新的特征,而且由于在Depthwise卷积中输出Feature Map的通道数等于输入Feature Map的通道数,因此它并没有升维或者降维的功能。
为了解决这些问题,v1中引入了Pointwise卷积用于特征合并以及升维或者降维。很自然的我们可以想到使用
卷积来完成这个功能。Pointwise的参数数量为
,计算量为:

综上,合并1.2中的Depthwise卷积和1.3中的Pointwise卷积便是v1中介绍的Depthwise Separable卷积。它的一组操作(一次Depthwise卷积加一次Pointwise卷积)的参数数量为: 是普通卷积的
MobileNetV2: MobileNetV1 + ResNet
MobileNetV1缺点
ReLU一定会带来信息损耗,而且这种损耗是没有办法恢复的,ReLU的信息损耗是当通道数非常少的时候更为明显。

根据对上面提到的信息损耗问题分析,我们可以有两种解决方案:
既然是ReLU导致的信息损耗,那么我们就将ReLU替换成线性激活函数;
如果比较多的通道数能减少信息损耗,那么我们就使用更多的通道。
我们当然不能把ReLU全部换成线性激活函数,不然网络将会退化为单层神经网络,一个折中方案是在输出Feature Map的通道数较少的时候也就是bottleneck部分使用线性激活函数,其它时候使用ReLU。代码片段如下:
1 | def _bottleneck(inputs, nb_filters, t): |
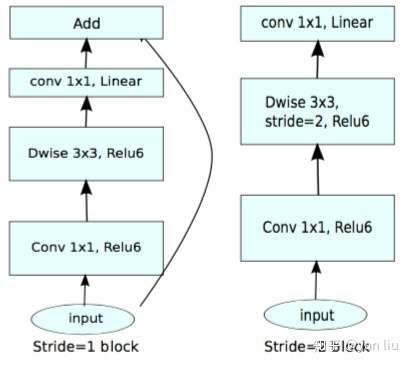
图7便是结合了残差网络和线性激活函数的MobileNet v2的一个block,最右侧是v1。
反残差:Inverted Residual
当激活函数使用ReLU时,我们可以通过增加通道数来减少信息的损耗,使用参数 来控制,该层的通道数是输入Feature Map的
倍。传统的残差块的
一般取小于1的小数,常见的取值为0.1,而在v2中这个值一般是介于
之间的数,在作者的实验中,
。考虑到残差网络和v2的
的不同取值范围,他们分别形成了锥子形(两头小中间大)和沙漏形(两头大中间小)的结构,如图8所示,其中斜线Feature Map表示使用的是线性激活函数。这也就是为什么这种形式的卷积block被叫做Interved Residual block,因为他把short-cut转移到了bottleneck层。
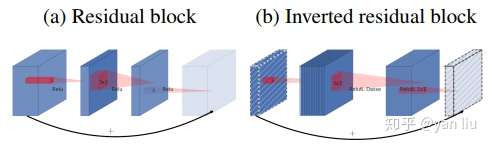
结论
obileNet v1最主要的贡献是使用了Depthwise Separable Convolution,它又可以拆分成Depthwise卷积和Pointwise卷积。MobileNet v2主要是将残差网络和Depthwise Separable卷积进行了结合。通过分析单通道的流形特征对残差块进行了改进,包括对中间层的扩展(d)以及bottleneck层的线性激活(c)。Depthwise Separable Convolution的分离式设计直接将模型压缩了8倍左右,但是精度并没有损失非常严重,这一点还是非常震撼的。
ShufferNetV1 VS ShufferNetV2
ShufferNetV1
实际上比如ResNeXt模型中1x1卷积基本上占据了93.4%的乘加运算。那么不如也对1x1卷积采用channel sparse connection,那样计算量就可以降下来了。但是group convolution存在另外一个弊端,
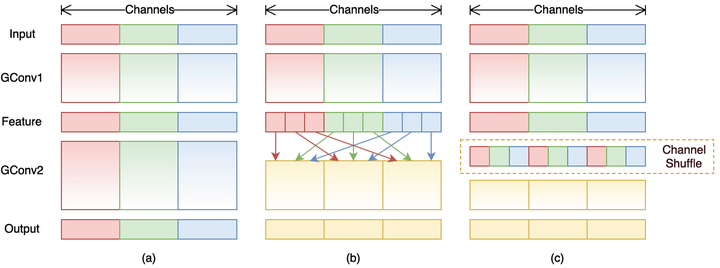
如图1-a所示,其中GConv是group convolution,这里分组数是3。可以看到当堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分了三个互不相干的路,大家各走各的,这目测会降低网络的特征提取能力。这样你也可以理解为什么Xception,MobileNet等网络采用密集的1x1卷积,因为要保证group convolution之后不同组的特征图之间的信息交流。
但是达到上面那个目的,我们不一定非要采用dense pointwise convolution。
如图1-b所示,你可以对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。
这个操作等价于图2-c,即group convolution之后对channels进行shuffle,但并不是随机的,其实是“均匀地打乱”。在程序上实现channel shuffle是非常容易的:假定将输入层分为 组,总通道数为
,首先你将通道那个维度拆分为
两个维度,然后将这两个维度转置变成
,最后重新reshape成一个维度。如果你不太理解这个操作,你可以试着动手去试一下,发现仅需要简单的维度操作和转置就可以实现均匀的shuffle。利用channel shuffle就可以充分发挥group convolution的优点,而避免其缺点。
ShuffleNet的基本单元
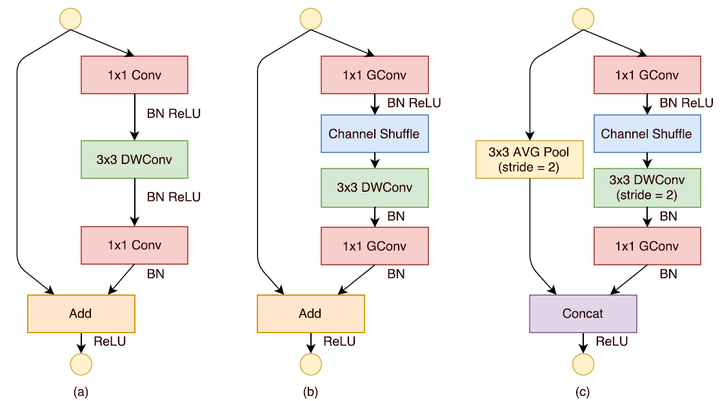
如图2-a所示,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
shufferNetV2
指导准则 :
(G1)同等通道大小最小化内存访问量 对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。这里假定输入和输出特征的通道数分别为 和
,特征图的空间大小为
,那么1x1卷积的FLOPs为
。对应的MAC为
(这里假定内存足够),根据均值不等式,固定
时,MAC存在下限(令
):
仅当 时,MAC取最小值,这个理论分析也通过实验得到证实,如表1所示,通道比为1:1时速度更快。
(G2)过量使用组卷积会增加MAC 组卷积(group convolution)是常用的设计组件,因为它可以减少复杂度却不损失模型容量。但是这里发现,分组过多会增加MAC。对于组卷积,FLOPs为 (其中
是组数),而对应的MAC为
。如果固定输入
以及
,那么MAC为:
可以看到,当
增加时,MAC会同时增加。这点也通过实验证实,所以明智之举是不要使用太大
的组卷积。
(G3)网络碎片化会降低并行度 一些网络如Inception,以及Auto ML自动产生的网络NASNET-A,它们倾向于采用“多路”结构,即存在一个lock中很多不同的小卷积或者pooling,这很容易造成网络碎片化,减低模型的并行度,相应速度会慢,这也可以通过实验得到证明。
(G4)不能忽略元素级操作 对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
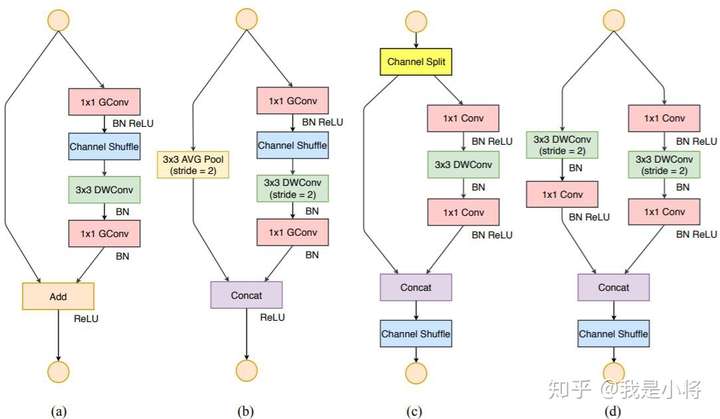
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。
为了改善v1的缺陷,v2版本引入了一种新的运算:channel split。具体来说,在开始时先将输入特征图在通道维度分成两个分支:通道数分别为 和
,实际实现时
。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
对于下采样模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
ShuffleNetv2的整体结构如表2所示,基本与v1类似,其中设定每个block的channel数,如0.5x,1x,可以调整模型的复杂度。
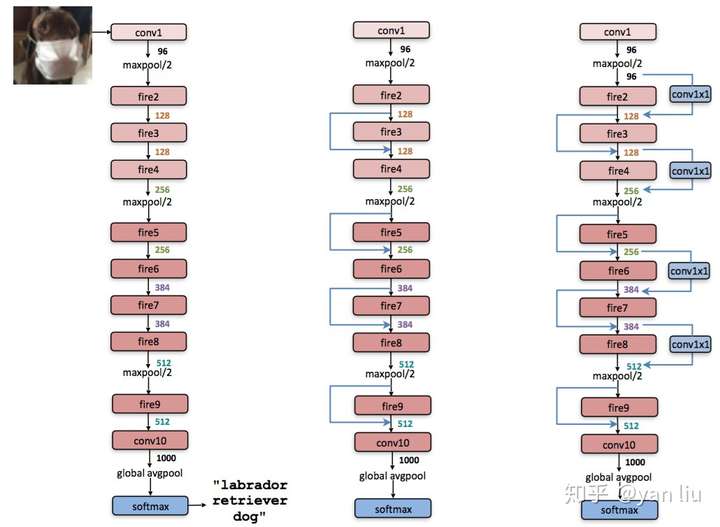
SqueezeNet
在不大幅降低模型精度的前提下,最大程度的提高运算速度。
提高运算所读有两个可以调整的方向:
- 减少可学习参数的数量;
- 减少整个网络的计算量。
这个方向带来的效果是非常明显的:
- 减少模型训练和测试时候的计算量,单个step的速度更快;
- 减小模型文件的大小,更利于模型的保存和传输;
- 可学习参数更少,网络占用的显存更小。
SqueezeNet的压缩策略
SqueezeNet的模型压缩使用了3个策略:
将
卷积替换成
减少
(其中
,
分别是输入Feature Map和输出Feature Map的通道数),作者任务这样一个计算量过于庞大,因此希望将
将降采样后置:作者认为较大的Feature Map含有更多的信息,因此将降采样往分类层移动。注意这样的操作虽然会提升网络的精度,但是它有一个非常严重的缺点:即会增加网络的计算量。
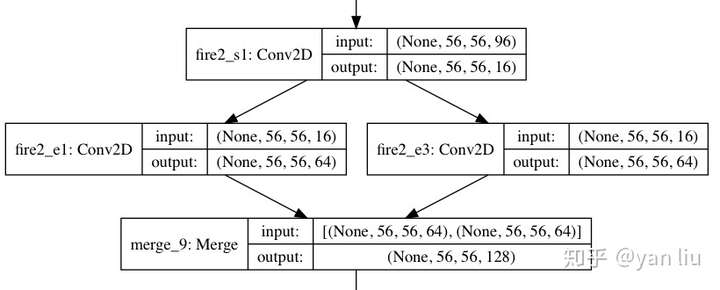
Fire模块
SqueezeNet是由若干个Fire模块结合卷积网络中卷积层,降采样层,全连接等层组成的。一个Fire模块由Squeeze部分和Expand部分组成(注意区分和Momenta的SENet[4]的区别)。Squeeze部分是一组连续的 卷积组成,Expand部分则是由一组连续的
卷积和一组连续的
卷积cancatnate组成,因此
卷积需要使用same卷积,Fire模块的结构见图1。在Fire模块中,Squeeze部分
卷积的通道数记做
,Expand部分
卷积和
卷积的通道数分别记做
和
(论文图画的不好,不要错误的理解成卷积的层数)。在Fire模块中,作者建议
,这么做相当于在两个
卷积的中间加入了瓶颈层,作者的实验中的一个策略是
。图1中
,
。

下面代码片段是Keras实现的Fire模块,注意拼接Feature Map的时候使用的是Cancatnate操作,这样不必要求 。
1 | def fire_model(x, s_1x1, e_1x1, e_3x3, fire_name): |
具体完整网络架构